The goal of this page is to understand how to implement a neural network from scratch without any external libraries. I’ll consider that you already have some basic knowledge of Artificial Neural Networks. The main reason for doing this is to demystify the black box of Neural Networks. For this project, the main resource (though not the only one) is this awesome video from Andrej Karpathy. I will cover how to implement AutoGrad for backpropagation. By the end of this post, you will be capable of creating MLPs from scratch!
Basic knowledge of derivative
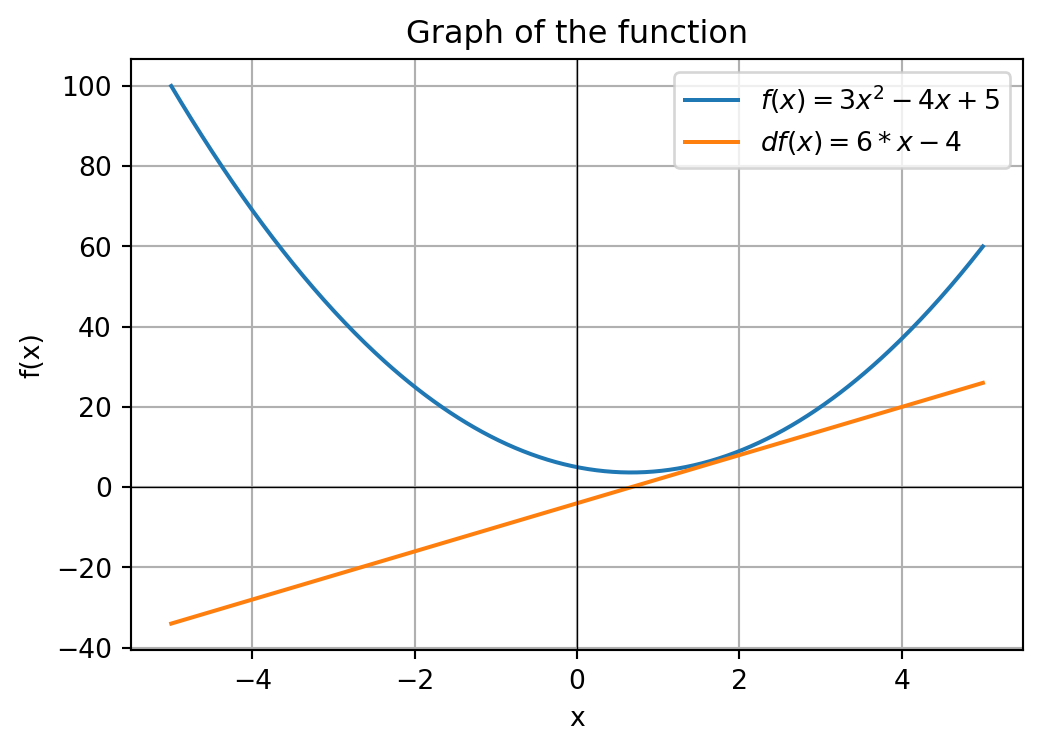
To make sense at how an NN train and learns, you first need a solid understand of what a derivative is. A derivative is an operation that gives us a formula that describes the slope of a function as it modifies a variable, but for out propose, we will only work with functions that generate linear derivatives. Thus, for the function \(f(x) = 3x^2 - 4x + 5\), see the graph below.
Show Python code
import numpy as npimport matplotlib.pyplot as plt# Define the functiondef f(x):return3*x**2-4*x +5# Generate x valuesx = np.linspace(-5, 5, 400)y = f(x)# Plotplt.figure(figsize=(6, 4))plt.plot(x, y, label=r"$f(x) = 3x^2 - 4x + 5$")plt.axhline(0, color="black", linewidth=0.5)plt.axvline(0, color="black", linewidth=0.5)plt.xlabel("x")plt.ylabel("f(x)")plt.title("Graph of the function")plt.legend()plt.grid(True)plt.show()
This function is easy to understand and derivate analytic, the derivate is \(\frac{df(x)}{dx} = 6x - 4\). Plotting both function and his derivate, we get the graphic below.
Show Python code
import numpy as npimport matplotlib.pyplot as plt# Define the functiondef f(x):return3*x**2-4*x +5def df(x):return6*x -4# Generate x valuesx = np.linspace(-5, 5, 400)y = f(x)y2 = df(x)# Plotplt.figure(figsize=(6, 4))plt.plot(x, y, label=r"$f(x) = 3x^2 - 4x + 5$")plt.plot(x, y2, label=r"$df(x) = 6*x - 4$")plt.axhline(0, color="black", linewidth=0.5)plt.axvline(0, color="black", linewidth=0.5)plt.xlabel("x")plt.ylabel("f(x)")plt.title("Graph of the function")plt.legend()plt.grid(True)plt.show()
The basic idea is that with we want to minimize the value of a function (main objective in deep learning), we just need to see the value of a derivative in some point A, that give us all the information we need to go to the minimum spot. Just do some numerical example, in the graph above, note that the minimum spot is in some value around 0 and 2, more close to 0 (precisely 2/3), so, just pick some random number, like -2, the value of \(f(x)\) with -2 is 25, and the derivative is -16. The number -16 represent the rate at which the function varies for each increase in the value of x at that point in specific. So, with we increase the value of X a little bit, we can lower the value of X, so probably, the \(f(-1.999)\) give us a lower value than \(f(-2)\)
This is the general idea of how we can minimize some function, that is also the main idea of how gradient descendent works.
How to estimate gradients
In general, to make an framework for working with nn, its just an AutoGrad (a tool that can do differentiation automatically) and some fancy stuff for make more practical.
For start, lets make things the most simple for now. Our goal its make an class that can calc for us all the gradients (its the same as an derivative) from the function \(L = -2 \cdot \big((2 \cdot 3) + 10\big)\). But we don’t are comfortable derivate something with just numbers, so lets consider in this way the function:
a =2b =-3.0c =10f =-2e = a*bd = e + cL = d * fL
-8.0
Just to make clear, the knowledge that we want with this, is ow much changes in the final result, increase the values of any of the variables a little To get the gradients, we can use an approximate that consists in adding a very small number \(h\) is all of the values, than subtract the new with the original, and divide by the \(h\). The code below shows how to do this with the variable \(a\):
a =2b =-3.0c =10f =-2e = a*bd = e + cL = d * fh =0.0001a =2+ hb =-3.0c =10f =-2e = a*bd = e + cL2 = d * fprint(f"L(2) = {L}")print(f"L({a}) = {L2}")print(f"The slope/gradient: {(L2 - L)/h}")
L(2) = -8.0
L(2.0001) = -7.999399999999998
The slope/gradient: 6.000000000021544
We will not use this method to create our autograd, but we can use this to verify with our gradients are right.
Lets making a simple AutoGrad
The basic idea of the AutoGrad we will make is make some very simple nodes, that represent the number in our calculation and will track all the last two nodes that make him. Basically, in \(L = -2 \cdot \big((2 \cdot 3) + 10\big)\), we will consider that a node can only save on number, like in the code representation
a =2b =-3.0c =10f =-2e = a*bd = e + cL = d * f
So, for start, lets make the basic of our class:
class Value:def__init__(self, data, _children=(), _op="", label=""):self.data = dataself.grad =0# All nodes will start with no grad, because we don't know what is the grad (and for other math reason will explain soon)self._prev =set(_children) # Don't worry about this for know, we only use set for a little bit better performanceself._op = _op # To save the operation, its useful for debugself.label = label # You can ignore this, its just for the graphs I make below# This is just for us visualize our classdef__repr__(self):returnf"Value(data={self.data})"
So with this class, we can create some Value’s, but we cant use them for anything, so lets make some operations
class Value:def__init__(self, data, _children=(), _op="", label=""):self.data = dataself.grad =0self._prev =set(_children) self._op = _opself.label = label # You can ignore this, its just for the graphs I make below# This is just for us visualize our classdef__repr__(self):returnf"Value(data={self.data})"def__add__(self, other):# We just add the data, and return a Value object with new data, and with pointes for the two number that make the out number out = Value(self.data + other.data, (self,other), '+')return outdef__mul__(self, other): out = Value(self.data * other.data, (self,other), "*")return out
And with this simples class, we can know calc our formula (not the gradients yet)
a = Value(2., label="a")b = Value(-3.0, label="b")c = Value(10., label="c")f = Value(-2., label="f")e = a * b; e.label="e"d = e + c; d.label="d"L = d * f; L.label="L"L
Value(data=-8.0)
This calculation is known as pass forward Below, simply make a graph to visualize the operations (note that the operator is not a real node, but to visualize this it is better). The question is: how can we get the gradients for \(L\), \(d\) and \(f\)?
For \(L\), I think it´s a little obvious, its just 1, from calculus, the derivative for the function \(f(x) = x\) its 1. For \(d\) and \(f\), we it´s simple too, from calculus, de derivative \(f(x) = zx\) its just z, and this is the case for both \(d\) and \(f\). See the equation below \[
L(d,f) = d \cdot f
\]\[
\frac{\partial L}{\partial d} = f \quad \text{and} \quad \frac{\partial L}{\partial f} = d
\]
So, the gradient for \(d\) is the value of data in \(f\), and for the \(f\), it´s the value of data in \(d\), in this case, the grad of \(d\) is -2 and the grad of \(f\) is 4.
Now its start being interesting, we want to calc the gradient of \(e\) and \(c\) in relation of \(L\). From the chain of rule, we have the expression below: \[
\frac{\partial L}{\partial e} = \frac{\partial L}{\partial d} \cdot \frac{\partial d}{\partial e}
\] Bascially, it´s saying that the gradient of \(e\) in relation with \(L\) it´s just the gradient of \(d\) in relation with \(L\) time \(e\) in relation with \(d\). This mean that we only have to calc the local gradient \(\frac{\partial d}{\partial e}\) because we already have calc the \(\frac{\partial L}{\partial d}\) and its save in d.grad. The same with \(c\) it´s true. So, from calculus, the gradient from an expression like \(f(x,y) = x + y\) its 1 for both \(x\) and \(y\). Thus, we have
This is the strong concept that make the AutoGrad work, we only need to calc the local gradient and multiply with the gradient from the father of nodes (because the gradient of the father already is in relation with the last node).
So for the last two variables \(a\) and \(b\), its another multiplication, so the local grad of \(b\) its data of \(a\), and for \(a\) its data from \(b\). Put in a code, its just
This is a complete backward pass manual, know we need to make a code to this automatically for us
Automatically backward pass
To do this automatically, you probably noticed that we need to start from the last node and work backwards (from the last to the first). The reverse order is necessary because for calculate the gradient of any node, we need the local gradient of the variable, and the gradient of the father, the unique exception is the last node, because its gradient always will be 1. he way we will implement this is by making each node responsible for calculating and passing the gradients down to its children. Let’s see how this works for the multiplication (mul) function::
class Value:def__init__(self, data, _children=(), _op="", label=""):self.data = dataself.grad =0self._backward =None# Add this new parameter too save the funcself._prev =set(_children) self._op = _opself.label = label def__mul__(self, other): out = Value(self.data * other.data, (self,other), '+')def _backward():# We use += instead of = to accumulate the gradients. # If we just used =, using the same node more than once would overwrite its gradient. # Since a single node can influence multiple forward paths, its total influence on the final result is the sum of the gradients from all those paths!self.grad += other.data * out.grad other.grad +=self.data * out.grad out._backward = _backwardreturn out
Lets check with this can calc the gradients of \(d\) and \(f\)
a = Value(2., label="a")b = Value(-3.0, label="b")c = Value(10., label="c")f = Value(-2., label="f")e = a * b; e.label="e"d = e + c; d.label="d"L = d * f; L.label="L"L.grad =1L._backward()print("Grad of d:", d.grad)print("Grad of f:", f.grad)
Grad of d: -2.0
Grad of f: 4.0
It works! So know, its just do for add too, below are the complete Value class
Show Python code
class Value:def__init__(self, data, _children=(), _op="", label=""):self.data = dataself.grad =0self._backward =lambda: None# Add this new parameter too save the funcself._prev =set(_children) self._op = _opself.label = label def__mul__(self, other): out = Value(self.data * other.data, (self,other), '+')def _backward():self.grad += other.data * out.grad other.grad +=self.data * out.grad out._backward = _backwardreturn out# This is just for us visualize our classdef__repr__(self):returnf"Value(data={self.data})"def__add__(self, other):# We just add the data, and return a Value object with new data, and with pointes for the two number that make the out number out = Value(self.data + other.data, (self,other), '+')def _backward():self.grad += out.grad other.grad += out.grad out._backward = _backwardreturn out
Lets check with we can calc all the gradients:
a = Value(2., label="a")b = Value(-3.0, label="b")c = Value(10., label="c")f = Value(-2., label="f")e = a * b; e.label="e"d = e + c; d.label="d"L = d * f; L.label="L"L.grad =1L._backward() # Node L: Propagates gradient to d and fd._backward() # Node d: Propagates gradient to e and cf._backward() # Node f (Leaf): Does nothing (empty lambda)e._backward() # Node e: Propagates gradient to a and bc._backward() # Node c (Leaf): Does nothingb._backward() # Node b (Leaf): Does nothinga._backward() # Node a (Leaf): Does nothingprint(f"L data: {L.data}")print("-"*20)print(f"Grad of L: {L.grad}") # Should be 1print(f"Grad of f: {f.grad}") # Should be 4.0 (d.data)print(f"Grad of d: {d.grad}") # Should be -2.0 (f.data)print(f"Grad of c: {c.grad}") # Should be -2.0 (1 * d.grad)print(f"Grad of e: {e.grad}") # Should be -2.0 (1 * d.grad)print(f"Grad of b: {b.grad}") # Should be -4.0 (a.data * e.grad -> 2 * -2)print(f"Grad of a: {a.grad}") # Should be 6.0 (b.data * e.grad -> -3 * -2)
L data: -8.0
--------------------
Grad of L: 1
Grad of f: 4.0
Grad of d: -2.0
Grad of c: -2.0
Grad of e: -2.0
Grad of b: -4.0
Grad of a: 6.0
It worked perfectly, know we only need to make a funcion that calls all _backward() in all nodes recursively. Therefore we will use an algorithm for generating the topological order of the graph. That is, a linear order in which we can execute the nodes without causing any kind of dependency problem. Explaining this algorithm in depth is outside the scope of this project, but it is not that complicated, see below:
# ... All methods of Value classdef backward(self):self.grad =1# Montar ordem topologica topo = [] visited =set()def build_topo(v):if v notin visited: visited.add(v)for child in v._prev: build_topo(child) topo.append(v) build_topo(self)for node inreversed(topo): node._backward()
Know, lets test our backward function
Show Python code
class Value:def__init__(self, data, _children=(), _op="", label=""):self.data = dataself.grad =0self._backward =lambda: None# Add this new parameter too save the funcself._prev =set(_children) self._op = _opself.label = label def__mul__(self, other): out = Value(self.data * other.data, (self,other), '+')def _backward():self.grad += other.data * out.grad other.grad +=self.data * out.grad out._backward = _backwardreturn out# This is just for us visualize our classdef__repr__(self):returnf"Value(data={self.data})"def__add__(self, other):# We just add the data, and return a Value object with new data, and with pointes for the two number that make the out number out = Value(self.data + other.data, (self,other), '+')def _backward():self.grad += out.grad other.grad += out.grad out._backward = _backwardreturn outdef backward(self):self.grad =1# create a topological order topo = [] visited =set()def build_topo(v):if v notin visited: visited.add(v)for child in v._prev: build_topo(child) topo.append(v) build_topo(self)for node inreversed(topo): node._backward()
a = Value(2., label="a")b = Value(-3.0, label="b")c = Value(10., label="c")f = Value(-2., label="f")e = a * b; e.label="e"d = e + c; d.label="d"L = d * f; L.label="L"L.backward() print(f"L data: {L.data}")print("-"*20)print(f"Grad of L: {L.grad}") # Should be 1print(f"Grad of f: {f.grad}") # Should be 4.0 (d.data)print(f"Grad of d: {d.grad}") # Should be -2.0 (f.data)print(f"Grad of c: {c.grad}") # Should be -2.0 (1 * d.grad)print(f"Grad of e: {e.grad}") # Should be -2.0 (1 * d.grad)print(f"Grad of b: {b.grad}") # Should be -4.0 (a.data * e.grad -> 2 * -2)print(f"Grad of a: {a.grad}") # Should be 6.0 (b.data * e.grad -> -3 * -2)
L data: -8.0
--------------------
Grad of L: 1
Grad of f: 4.0
Grad of d: -2.0
Grad of c: -2.0
Grad of e: -2.0
Grad of b: -4.0
Grad of a: 6.0
It´s worked perfectly again, know we already have a functional AutoGrad system, know, it´s just need to add more operations and we will be capable of create our propely framework of Deep Learning using our own AutoGrad. Before going to the next part, see the code bellow, its the same that we create together, but with some little changes, try to figure out what they’re for (Hint, they’re important for the next part)
class Value:def__init__(self, data, _children=(), _op="", label=""):self.data = dataself.grad =0self._backward =lambda: Noneself._prev =set(_children) self._op = _opself.label = label def__mul__(self, other): other = other ifisinstance(other, Value) else Value(other) out = Value(self.data * other.data, (self,other), '+')def _backward():self.grad += other.data * out.grad other.grad +=self.data * out.grad out._backward = _backwardreturn outdef__repr__(self):returnf"Value(data={self.data})"def__add__(self, other): other = other ifisinstance(other, Value) else Value(other) out = Value(self.data + other.data, (self,other), '+')def _backward():self.grad += out.grad other.grad += out.grad out._backward = _backwardreturn outdef__pow__(self, other):assertisinstance(other, (int, float)), "only supporting int/float powers for now" out = Value(self.data**other, (self,), f'**{other}')def _backward():self.grad += (other *self.data**(other-1)) * out.grad out._backward = _backwardreturn outdef__neg__(self): returnself*-1def__sub__(self, other): returnself+ (-other)def__radd__(self, other): returnself+ otherdef backward(self):self.grad =1# create a topological order topo = [] visited =set()def build_topo(v):if v notin visited: visited.add(v)for child in v._prev: build_topo(child) topo.append(v) build_topo(self)for node inreversed(topo): node._backward()
Lets make our Deep Learning framework
Building a Neuron
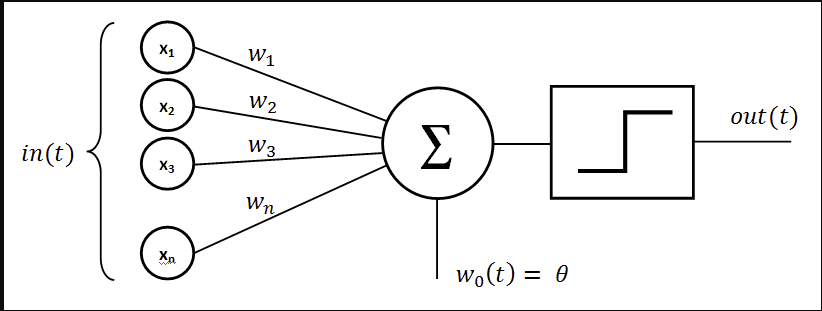
So, for now, we have already created our own engine to calculate our gradients. Thus, lets start making a simple artificial neuron. If you don’t know or don’t remember how a neuron work, basically it receives inputs, multiply each one by some weight, sum all values, and last, pass this value in a non-linear function
Figure 1: An Artificial Neuron
To start, we can make a simple class for our neuron:
import randomclass Neuron:def__init__(self, input_num, non_linear=True):self.w = [Value(random.uniform(-1,1)) for _ inrange(input_num)] # This basicaly creates a list of Value's from a uniform distribuition with lenth equals to input_numself.b = Value(random.uniform(-1,1)) # This is for the bias, explain deeply the importance of this is out of scope, but you can think bias its just a special weight that dosnt multiply the inputs, just sum in the sum part.# Call is a special function in python, its like __add__, the sintax for use this is when you just put () after the object, like range(x)def__call__(self,x): out =sum((wi*xi for wi,xi inzip(self.w, x)), self.b) # This just do the calculation of a neuron until the sum partreturn outdef parameters(self):returnself.w + [self.b] # this function just return all the parameters of our neuron
And, its just it, a completely and functional artificial neuron.
Know, lets test if this are working
n = Neuron(2)x = [2, 3, 4]out = n(x)print(out, n.parameters())
So, we already create an simple Neuron, now, we just need to line them up for make a Layer.
class Layer:def__init__(self, input_num, output_num, non_linear=True):self.neurons = [Neuron(input_num) for _ inrange(output_num)] # Create a list of neurons that accept input_num variables in input, and will generate output_num outputsself.non_linear = non_linear# Just process all operations in all neurons with the inputdef__call__(self,x): outs = [n(x) for n inself.neurons]ifself.non_linear: outs = [out.tanh() for out in outs]return outs[0] iflen(outs) ==1else outsdef parameters(self): out = []for neuron inself.neurons: out.extend(neuron.parameters()) # Add the values in an unique listreturn out
For this Layer class, we need to implement the tanh (tangent hyperbolic) function. It’s formula is: \[
\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
\]
Note that there is 3 operations that we don’t implement to make this, so, lets implement them. For know, I presume that you understand how to implement this, so, try your self, you can search in google for this, just don’t use an llm.
Show solution:
import math# Its not really necessary to add exp, subtraction or divided, but its good with you do 😊def tanh(self): x =self.data t = (math.exp(x) - math.exp(-x))/ (math.exp(x) + math.exp(-x)) out = Value(t, (self,), "tanh")# We can derivate, or just pick up on googledef _backwards():self.grad += (1- t**2) * out.grad out._backward = _backwardreturn out
Let’s test if this work
x = [2, 3, 4]layer = Layer(3,3)layer(x), layer.parameters()
Work well, this is pretty simple too. Now let’s move to the last part, create an complete Artificial Neural Network
Building an MLP
For last, we will create a Multilayer Perceptron, for this, we just need to line layer up.
class MLP:def__init__(self, input_num, outputs_nums):self.layers = [] values = [input_num] + outputs_numsforidinrange(len(outputs_nums)-1): # This work for create an unique list used to describe input and output for all layersself.layers.append(Layer(values[id], values[id+1]))self.layers.append(Layer(values[-2], values[-1], non_linear=False))def__call__(self, X):for layer inself.layers: # This works because with exception from the first, each layer just receive the input from the last layer X = layer(X)return Xdef parameters(self): out = []for layer inself.layers: out.extend(layer.parameters())return out
And, its finish, just need to test now
nn = MLP(3, [6,6,1])x = [2, 3, 4]nn(x) # You can test the parameters
Value(data=-1.2856428456237947)
Training our neural network
In the last part, we create a MLP, but we don’t fit them in any data. Lets create a function and values with some noise
import randomdef f(x,y,z):return0.04*x**2+0.07*y*x - z + random.gauss(0, 1)/5X = [] y = [] for i inrange(100): X.append([random.uniform(-5,5) for _ inrange(3)]) y.append(f(X[i][0],X[i][1],X[i][2]))
To implement the train loop, we will need one more thing, there is an loss functions, this is just an metric that describes how well our model are fitting in data. For these case, we will use Mean Squared Error, so the steps for the training loop, its, calc the prediction, calc the loss, calc the gradients, subtract the gradients from the weights, reset the gradients values (our code accumulate the gradients) and do it again, and again.
ann = MLP(3, [8, 8, 1]) for i inrange(50): # Our code will do 50 epochs of training y_pred = [ann(x) for x in X] # Our model only accept one prediction per time loss =sum((pred-origin)**2for pred,origin inzip(y_pred, y)) * (Value((len(y))) **-1) # You can implement the division operator or do it this way loss.backward() # Calc of gradients for p in ann.parameters(): p.data = p.data -0.01*p.grad # Updating weights, we multiply the gradient by a small number called learning rate, we do this for not have problems with model convergence p.grad =0# Reset the gradients, with we don't do this, our grad will increase infinitelyprint(f"Epoch {i}, Loss: {loss}")
Work, it’s probability possible to improve this changing the activation function by an ReLU. But for our propose, it’s good enough. Lets just see the values coming from our model